
TL;DR
- AI-powered code generation can produce functional C/C++ modules, transforms, and utilities quickly, accelerating early development.
- But embedded systems require behavioural correctness, stable timing, predictable memory access, consistent traversal, and repeatable iteration cost, not just functional correctness.
- Because AI models lack hardware awareness, they often introduce structural issues like scattered memory access, temporary buffers, or unpredictable branching that destabilize execution when loops run continuously.
- These behavioural problems rarely appear in code review but become immediately visible on real devices where micro-inefficiencies accumulate into jitter, timing drift, and throughput degradation.
- WedoLow closes this gap by analysing how code actually behaves at runtime, then proposing or applying behaviour-aware restructurings (automated when safe; validated before commit) so the final C/C++ remains functionally identical but executes predictably across iterations.
Introduction: Why embedded constraints change code priorities
AI-assisted code generation accelerates prototyping but does not guarantee stable execution. Modern models can generate full modules, geometric transforms, and interpolation utilities from natural language, allowing developers to assemble functional scaffolding in minutes. This speed enables early exploration, but clean, correct source code does not guarantee predictable behaviour when that code runs repeatedly on constrained hardware.
Embedded workloads prioritize behavioural correctness, not just functional correctness. These systems rely on stable timing, consistent traversal, and predictable memory access; even small structural shifts, a temporary buffer inside a hot loop, a re-ordered stride, or a branch that fires intermittently, can introduce jitter, throughput loss, or drift across frames. Pipelines such as CARS Rasterize, CARS Resample, and Ruckig-style motion loops highlight this gap clearly because execution stability matters as much as numerical correctness.
Before moving on, here is a quick overview of the workloads referenced throughout the article:
- CARS Rasterize: A tile-based rasterization pipeline that processes image tiles in tight, repeatable loops. Performance depends heavily on stable per-tile timing and predictable memory traversal.
- CARS Resample: A high-throughput resampling pipeline sensitive to stride, locality, and uniform row-processing cost. Small changes in index math or workspace layout immediately result in per-row timing drift.
- Ruckig-style motion planning: A real-time trajectory-update loop used in robotics. It must maintain nearly identical cycle cost across updates to ensure smooth actuator motion; even tiny timing variations become visible as jitter.
Pipelines like these clearly highlight the behavioural gap, because execution stability matters as much as numerical correctness. Tools that observe runtime behaviour, including timing spread, traversal stability, and memory patterns, are becoming essential companions to AI generation. In the sections ahead, you’ll see how AI-generated code behaves in real embedded workloads, where functional correctness breaks down into behavioural instability, and how the ecosystem is shifting toward generator-plus-critic workflows that make embedded execution more predictable.
What AI Code Generation Looks Like Today
AI-generated code creates strong first impressions but only solves the functional layer. The output often arrives cleanly structured, readable, and logically coherent, making it feel production-ready at a glance. Developers can request transforms, iterators, or interpolation utilities, and the model assembles functional scaffolding that compiles and passes early checks. This speed materially changes how teams prototype, because modules that once required hours of setup now materialise in minutes.
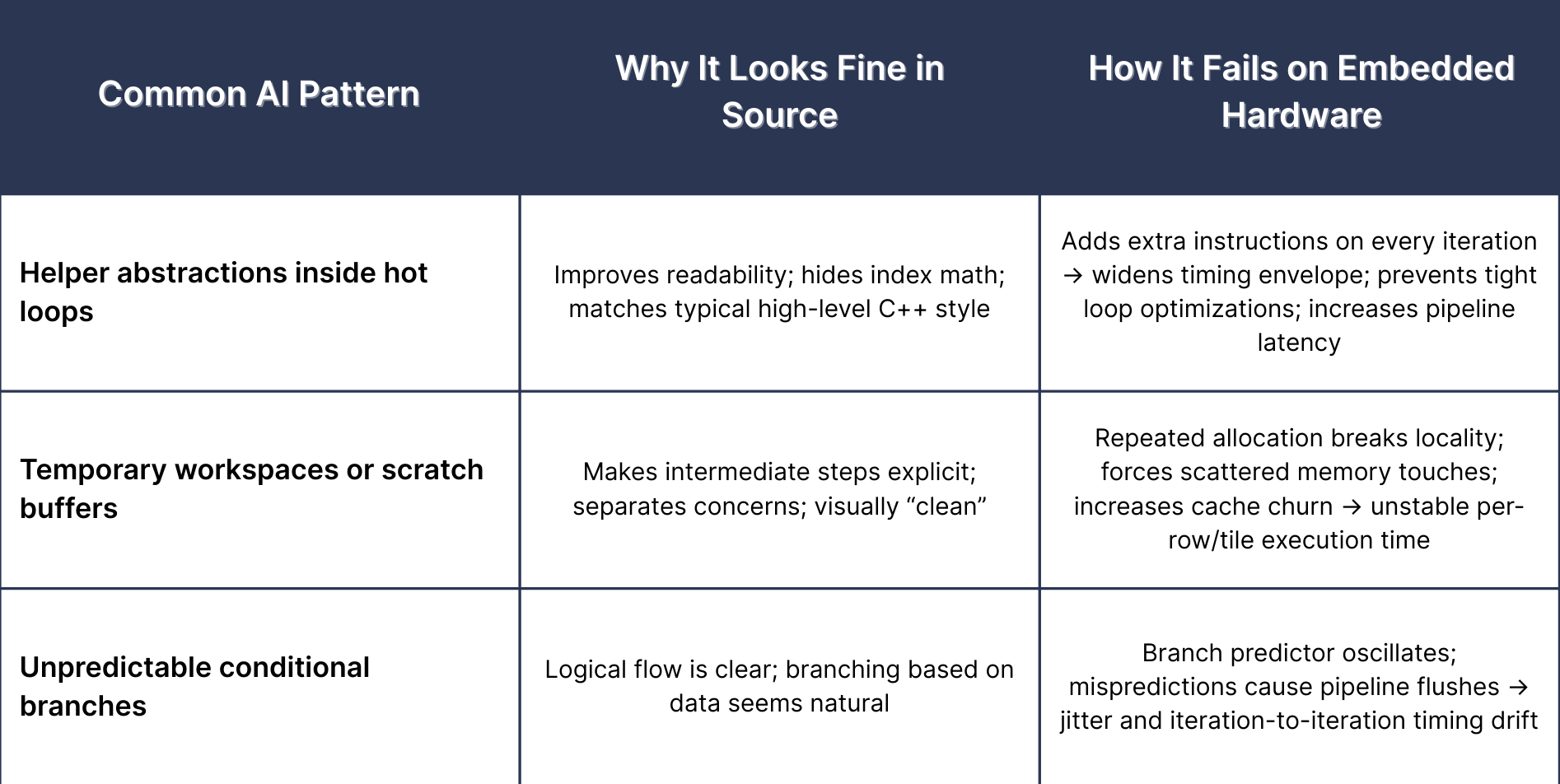
Embedded workloads expose behavioural weaknesses that the source code does not reveal. The gap appears once the code enters tight loops and real-time paths where predictable memory access, branch stability, and consistent iteration cost matter as much as correctness. AI-generated structures often drift here because the model optimizes for clarity rather than execution behaviour. Three patterns show up repeatedly in embedded pipelines:
- Seemingly harmless abstractions destabilise hot loops. A helper function or index wrapper added inside an inner loop may look elegant, but each invocation adds subtle overhead that compounds across thousands of iterations. On embedded hardware, even a few extra instructions per pass widen the timing envelope enough to degrade throughput.
- Temporary workspaces distort memory patterns. AI frequently introduces small buffers or short-lived containers to “keep code clean.” These allocations are cheap in isolation but reduce locality when repeated inside tile or frame loops. The effect shows up as irregular stride, extra cache misses, or inconsistent traversal timing.
- Conditionals that fire unpredictably create jitter. Branches triggered only under certain numeric ranges may seem logically sound, but disrupt branch prediction and cycle consistency. Embedded systems feel these irregularities almost immediately, because timing deviations accumulate across frames and break deterministic scheduling.
These patterns look harmless during review but create measurable instability under continuous execution. Behaviour-aware validation is therefore becoming essential: early tests rarely surface these structural issues; they appear only when implementations run repeatedly on real devices. Tools that observe runtime behaviour, measuring timing spread, traversal instability, and memory access irregularities, surface the structural drift that generators miss. The sections that follow unpack these patterns in detail and explain why behavioural correctness, not just functional correctness, is now the real bar for AI-generated embedded code.
Strong at Producing Functional Code Quickly
AI generation dramatically speeds up early development. Modern models produce organised, compilable C/C++ modules, transforms, iterators, resamplers, and control helpers, almost instantly from natural-language prompts. That instantaneous scaffolding lets teams validate ideas, run quick experiments, and iterate on algorithm choices without spending days writing boilerplate.
This speed is especially valuable during prototyping. When exploring rasterization variants or motion-update strategies, developers can spawn working modules and compare approaches rapidly. The generated code usually reads well, compiles cleanly, and passes first-order checks, making it a powerful productivity multiplier for early-stage design and validation.
But generated code often lacks hardware awareness. Embedded systems judge code by behaviour, not just by whether it computes the right result: they expect stable timing, consistent traversal, and predictable memory access across thousands of iterations. Small structural choices, a helper inside a hot loop, an index remap that scatters reads, or an intermittent branch, can be functionally correct yet produce measurable jitter, throughput loss, or cache pressure on real devices.
Concrete example, preserve stride, hoist row work, keep inner loop tight. The snippet below shows a common AI pattern (index remapping inside the inner loop) and a production-friendly refactor that hoists per-row mapping and reads contiguous memory where possible. The example adds a defensive bounds check and documents layout assumptions that matter on constrained targets.
/* Problem: index remapping inside the inner loop can turn sequential scans into scattered reads.
Goal: preserve spatial stride, hoist per-row work, keep inner loop tight. */
for (int y = 0; y < H; ++y) {
int ny = map_y[y]; /* hoist per-row mapping */
const float *grid_row = grid[ny]; /* assume grid is row-major and grid_row points to W elements */
const float *offsets_row = offsets[y];
float *out_row = output[y];
/* If map_x is not monotonic, consider building a small remap[] for the row that keeps memory locality */
for (int x = 0; x < W; ++x) {
int nx = map_x[x]; /* inexpensive index lookup */
/* defensive check avoids UB if map_x contains unexpected values (production builds only) */
if ((unsigned)nx >= (unsigned)W) {
nx = 0; /* or clamp/handle error according to project policy */
}
/* Attempt to read from contiguous memory where possible to preserve prefetch/stride */
float v = grid_row[nx];
float adjusted = apply_offset(v, offsets_row[x]); /* keep offsets access row-major */
out_row[x] = resample(v, adjusted);
}
}
/* Extra option: if map_x is mostly identity with occasional remaps, precompute monotonic segments
and iterate them to keep inner reads stride-friendly. */Behaviour-aware analysis helps close the gap. Tools that measure timing envelopes, traversal stability, and allocation hotspots make these differences visible and produce actionable diagnostics that guide generators (or engineers) to prefer stride-preserving, hoisted patterns over scattered inner-loop remaps.
Limited Ability to Optimize for Embedded Performance
AI-generated code favours readability over microarchitectural efficiency. The model gravitates toward expressive structures, helpers, temporary buffers, and generalized abstractions, because these patterns dominate its training data. Embedded systems, however, depend on alignment, locality, vectorization, and branch predictability. These low-level behaviours dictate real cycle cost, and AI models have no visibility into how a processor reacts when code runs for thousands of iterations.
Note: Vectorization gains depend on compiler heuristics, target ISA, and build flags; verify benefits with compiler reports or consider platform intrinsics where necessary.
Small inefficiencies compound dramatically in embedded pipelines. Redundant arithmetic inside an inner loop, traversal that disrupts stride, or a branch that fires only some iterations may look harmless, but generate measurable timing drift when repeated millions of times. Computing coordinate transforms inside a rasterizer’s inner loop widens the per-tile timing envelope. Allocating a tiny buffer each frame in a motion loop introduces allocator jitter that eventually manifests as visible control jitter.
AI lacks feedback about hardware-level execution constraints. Without timing data, locality maps, or branch profile feedback, the model cannot anticipate how cache alignment, TLB locality, or allocator latency affects real hardware. The result is functionally correct but behaviourally unstable C/C++, a mismatch that embedded systems always expose.
Concrete Example: Eliminating Allocator Jitter and Intermittent Branching
The pattern below appears frequently in AI-generated trajectory-update loops:
- intermittent if paths that destabilize per-iteration cycle cost,
- per-iteration heap allocation inside the hot path,
- no workspace reuse or second-pass correction strategy.
Problematic AI-generated pattern
/* Problem: per-iteration malloc/free and intermittent branches create allocator jitter and timing variance.
Fix: use a preallocated workspace (per-thread or per-frame) and isolate expensive corrections from the hot loop. */
/* Preallocate once (stack or static per-thread buffer). On constrained targets, avoid dynamic allocation. */
static float workspace[MAX_UPDATES]; /* MAX_UPDATES >= count or use per-thread storage */
for (int i = 0; i < count; ++i) {
float acc = compute_acc(state[i]);
/* Intermittent branch creates iteration-to-iteration timing variance */
if (acc > limit) {
acc = correct_acc(acc, state[i]); /* heavy path hits unpredictably */
}
workspace[i] = compute_jerk(acc);
jerk[i] = workspace[i];
}Embedded-safe refactor: Uniform hot loop + two-pass correction
/* Option A: keep hot loop uniform; correct rare cases separately */
static float workspace[MAX_UPDATES];
static uint8_t needs_correction[MAX_UPDATES]; /* flags for second pass */
for (int i = 0; i < count; ++i) {
float acc = compute_acc(state[i]);
/* record whether this iteration needs correction, but avoid heavy work here */
needs_correction[i] = (acc > limit);
/* keep hot loop predictable and branch-stable */
float clipped = (acc > limit) ? limit : acc; /* cheap, predictable clamp */
workspace[i] = compute_jerk(clipped);
jerk[i] = workspace[i];
}
/* Second pass: handle only rare heavy corrections */
for (int i = 0; i < count; ++i) {
if (needs_correction[i]) {
float acc = correct_acc(compute_acc(state[i]), state[i]);
jerk[i] = compute_jerk(acc); /* overwrite corrected value */
}
}Why this matters
- The hot loop becomes iteration-uniform, same instructions, same memory access pattern.
- Heavy corrective work moves to a sparse secondary pass, where its cost does not destabilize timing.
- Cycle-count variance collapses, eliminating a common source of jitter in Ruckig-style update loops.
Why AI Code Struggles in Embedded Workloads
Embedded systems amplify even small structural deviations. A helper inside a hot loop, a tiny temporary buffer allocated per tile, or a remap that breaks stride may look benign in the source but becomes immediately visible on hardware. CARS Rasterize and Resample pipelines rely on tight per-tile timing envelopes; even slight deviations widen them.
Real-time motion loops make this sensitivity unavoidable. Each update must match the previous iteration’s timing. Any non-uniform branch, heap interaction, or scattered memory access becomes visible as actuator jitter. These are not logic errors; they are behavioural inconsistencies compounded over thousands of frames.
To AI, these patterns look harmless; to hardware, they are destabilizing. Models cannot infer cache reuse, loop-carried dependencies, branch predictor behaviour, or memory stride effects. These issues surface only during execution, never in static review.
+-----------------------+
| 1. Execute workload |
| under real input |
+-----------+-----------+
|
v
+-----------------------+
| 2. Capture behaviour |
| - timing envelope |
| - memory stride map |
| - branch variability |
+-----------+-----------+
|
v
+-----------------------+
| 3. Detect drift & |
| structural causes |
+-----------+-----------+
|
v
+-----------------------+
| 4. Suggest or validate|
| structural fixes |
+-----------+-----------+
|
v
+-----------------------+
| 5. Re-run & confirm |
| stable behaviour |
+-----------------------+

Behaviour-Aware Tooling Closes the Feedback Gap
Behaviour-aware tools bridge functional correctness and behavioural correctness. Instead of inspecting code text, they execute it under representative workloads, measure iteration-to-iteration timing, examine traversal stability, detect scattered memory access, and identify allocation hotspots. The resulting feedback, timing envelopes, drift signatures, and locality maps highlight the structural causes of instability and guide regeneration or manual refactoring.
The outcome is critical for embedded systems: functionally identical C/C++ that behaves predictably across iterations, preserving the tight timing and stable memory patterns needed for real-time workloads.
Deterministic Timing Requirements
Deterministic timing is a core requirement in embedded pipelines. Many real-time workloads expect each iteration to take the same amount of time, not just on average, but within a narrow cycle band across thousands of frames. In CARS Rasterize, for example, every tile must follow a stable execution pattern so the scheduler can maintain throughput. Even small AI-introduced variations, a conditional that fires only for certain tiles, a temporary buffer created in selective cases, or a traversal change based on input shape, widen the timing envelope and reduce pipeline predictability.
Row-based algorithms show the same fragility. CARS Resample assumes a consistent stride, predictable cache touches, and uniform row-processing cost. AI-generated rewrites that reorganize index math or introduce a temporary workspace may look cleaner, but they shift per-row timing once the workload repeats. Over large datasets, these micro-variations accumulate into visible throughput dips, especially when several threads must progress in lockstep.
Motion-planning loops highlight how quickly timing drift becomes jitter. Ruckig-style control updates depend on iteration-to-iteration stability: each update must take the same number of cycles to maintain smooth motion. AI-generated logic that adds intermittent branches, clamps, or per-iteration allocations introduces small timing shifts that compound across hundreds of frames. The numeric trajectory remains correct, but the motion becomes visibly uneven.
Concrete Example: Eliminating Per-Tile Timing Drift
The snippet below illustrates a typical AI-generated pattern in tile-processing workloads:
- a per-tile temporary buffer allocated implicitly on the stack,
- conditional adjustments that alter work only for edge tiles,
- and a hot inner loop whose cost varies across tiles.
Problematic AI-style pattern
/* Problem: per-tile stack workspace + conditional in hot path causes timing variance across tiles. */
static float thread_workspace[THREAD_MAX][256]; /* THREAD_MAX provided by platform */
float *workspace = thread_workspace[thread_id]; /* workspace reused across tiles */
for (int t = 0; t < tile_count; ++t) {
/* compute_intermediate writes into workspace */
compute_intermediate(tile[t].points, workspace);
/* Conditional branch fires only for edge tiles, this shifts per-tile cycle cost */
if (tile[t].is_edge) {
adjust_for_edges(workspace, tile[t].size);
}
/* Hot loop should be uniform, but upstream variation leaks into tile timing */
int out_off = tile_output_offset(t);
for (int i = 0; i < tile[t].size; ++i) {
output[out_off + i] = project_to_surface(workspace[i]);
}
}Embedded-Safe Refactor: Uniform Hot Path, Isolated Corrections
/* Fix: ensure the projection loop is identical for every tile and isolate edge-specific work. */
static float thread_workspace[THREAD_MAX][256];
float *workspace = thread_workspace[thread_id];
for (int t = 0; t < tile_count; ++t) {
compute_intermediate(tile[t].points, workspace);
/* Move rare, tile-specific adjustments before the hot loop and keep them shallow */
if (tile[t].is_edge) {
adjust_for_edges(workspace, tile[t].size);
}
/* Hot loop: deterministic, identical work for each tile */
int out_off = tile_output_offset(t);
for (int i = 0; i < tile[t].size; ++i) {
output[out_off + i] = project_to_surface(workspace[i]);
}
}Why this works
- The inner loop performs the same operations for every tile, ensuring stable cycle counts.
- Per-tile corrections are isolated and cannot contaminate the projection loop’s timing.
- The reusable workspace eliminates per-tile allocation variance and improves locality.
Deterministic Timing Requires Behaviour-Level Visibility
These issues are invisible in source form but obvious in execution. A conditional branch in a tile loop, a scattered traversal, or a stack buffer used inconsistently may not look wrong, yet the hardware reflects these differences immediately in cycle-count drift.
Behaviour-aware tooling makes this measurable. By capturing iteration-to-iteration timing stability, memory-touch patterns, and branch behaviour under realistic workloads, such systems reveal exactly where structural drift occurs and guide refactoring toward deterministic loop shapes.
The result: functionally identical C/C++ whose timing profile is stable enough for real-time embedded pipelines.
Tight Memory & Cache Constraints
Embedded systems lack the memory elasticity and cache behaviour of general-purpose servers. Their performance depends heavily on predictable locality, stable traversal, and minimizing unnecessary memory movement. Even minor changes in memory access order shift cycle cost across iterations, and these shifts accumulate quickly in pipelines that execute thousands of passes per frame, particularly in CARS Rasterize, CARS Resample, and Ruckig-style control loops.
AI-generated code regularly violates these constraints without realizing it. It might insert temporary arrays into inner loops, introduce container operations with poor locality, or reorganise traversal into non-linear sequences that force the processor to fetch data from scattered locations. These patterns appear clean and reasonable at the source level: a helper function, a vector push, and a temporary workspace, but they degrade locality and create unpredictable stalls when executed repeatedly at scale.
Consider this typical issue in a CARS Rasterize-like pipeline: AI-generated code may insert an intermediate coordinate pass inside the inner tile-processing loop. Although functionally correct, this breaks the sequential left-to-right memory walk that the pipeline relies on to maintain stable timing. The result is subtle per-tile timing variation that grows over long execution windows.
CARS Resample shows another example: AI-generated rewrites often reorganise index calculation formulas. The math remains correct, but the memory access pattern becomes scattered rather than linear. Throughput drops because the processor cannot maintain a predictable stride, leading to frequent misses and inconsistent per-row performance.
Ruckig-like motion loops suffer from similar issues. In one AI-generated version, a temporary buffer was allocated each frame to hold intermediate jerk values. The allocation was tiny, a single float, but its presence inside a high-frequency loop introduced measurable timing variance. When repeated across many iterations, these micro variations accumulate into behaviourally noticeable jitter.
These are not programming mistakes. They are structural consequences of AI-generated code lacking an intuition for locality, stride, prefetch behaviour, and per-iteration memory cost.
WedoLow addresses this challenge by analysing memory-access patterns across time, identifying where locality is disrupted, and restructuring traversal and workspace usage to restore stability. The beLow engine applies memory-related optimisations that eliminate unnecessary allocations, reinforce sequential access, and stabilise per-iteration cost. When these corrections are fed to the connected AI agent (MCP is used only as the secure transport), the agent regenerates code using the updated execution context, producing code that naturally aligns with embedded memory expectations.
The Current Limitations of AI-Powered Embedded Code Generation
AI-generated code accelerates development, but embedded workloads expose weaknesses that remain invisible at the source level. When a pipeline runs thousands of iterations per frame, such as CARS Rasterize, CARS Resample, or Ruckig-inspired trajectory updates, even small structural deviations introduced by AI accumulate into measurable instability. These problems fall into three specific categories: hidden inefficiencies, loss of deterministic timing, and performance degradation under load.
Below is a refined breakdown of these risks as they appear in real embedded workloads.
Over-Abstraction & Heap Usage
AI models gravitate toward expressive, generalised patterns. They insert dynamic containers, helper abstractions, and temporary buffers because such structures are common in general-purpose C++ training data. But embedded systems rely on locality, predictable allocation, and minimal abstraction, and even small dynamic behaviours can destabilise long-running workloads.
In a CARS-Rasterize like pipeline, AI might allocate a std::vector<float> inside each tile iteration to hold intermediate coordinates. The code looks harmless, clean, readable, and modern, yet this temporary buffer adds heap traffic and disrupts e-cost variance across tiles.
Similar issues appear in CARS Resample when AI introduces generalised indexing helpers that allocate scratch storage per row. These allocations are tiny but repeated thousands of times, causing unpredictable cache behaviour and memory stalls.
These inefficiencies are invisible during code review, but WedoLow surfaces them immediately.
Through behaviour-level analysis, WedoLow identifies repeated heap touches, redundant abstraction layers, and temporary allocations that fragment the iteration path. It then restructures these regions, removing dynamic buffers, inlining safe paths, and restoring locality, so the code behaves predictably without losing correctness.
Non-Deterministic Execution
Embedded systems depend on repeatable timing. A loop that takes 2000 cycles today must take 2000 cycles tomorrow; otherwise, jitter, drift, or scheduling instability appears.
AI-generated code often violates this principle because it introduces conditional logic, helper functions, or state-dependent patterns that can subtly change the time each iteration takes.
In Ruckig-style update loops, for example, AI may insert a seemingly harmless conditional check around jerk computation. It fires only under specific numeric ranges, making some iterations heavier than others. The trajectory remains mathematically correct, but the execution timing fluctuates between frames, producing motion jitter.
Likewise, in CARS Rasterize, AI-generated logic might adjust tile parameters only when encountering certain edge tiles. Those branches do not affect correctness, but they cause irregular cycle cost, widening the timing envelope across thousands of tiles.
These issues cannot be diagnosed visually. The code appears structured and valid.
But WedoLow identifies these unstable patterns by measuring execution behaviour across dozens or hundreds of iterations. Its analysis highlights where branches fire unpredictably or where control flow changes the runtime cost. With this behavioural insight, WedoLow reshapes the code into stable, uniform paths that keep cycle counts consistent while preserving functionality.
Performance Regression vs Hand-Written Code
Even when AI-generated code is logically correct, it often underperforms hand-tuned embedded C/C++. The model optimises for readability, abstraction, and structural clarity, not alignment, vectorization, or memory traversal patterns.
AI-generated structural drift often leads to predictable regressions, such as redundant recalculations inside inner loops, traversal patterns that become non-sequential and hurt memory locality, unnecessary type conversions that break vectorization, helper function calls that bloat the hot path, and loop bodies that become so scattered that the compiler can no longer apply effective auto-optimisations.
In a CARS Resample workload, for instance, the AI may rewrite the traversal logic to look clean but destroy sequential memory walking. The pipeline becomes dependent on scattered reads, leading to increased cache misses and degraded throughput.
In a simplified tile rasterization path, AI-generated code might move intermediate computations inside the inner loop, producing correct output, but at a cost of higher cycles per tile and wider runtime variance.
WedoLow detects these regressions by analysing execution behaviour and memory-access patterns.
Once identified, WedoLow restructures the critical path: simplifying loop bodies, restoring sequential traversal, eliminating unnecessary transforms, and tightening operations so compiler optimisations can kick in. The result is code that behaves like hand-written embedded logic, but without requiring the developer to manually rewrite every path.
Landscape and diagnosis: Behaviour vs. functional correctness
Behaviour and diagnosis: the gap between functional code and behavioural correctness
AI-generated code often nails functional correctness but misses how code actually behaves on hardware. In embedded contexts, the difference matters: timing envelopes, traversal order, memory stride, and repeatable cycle cost determine whether a module is usable, not just whether it computes the right numbers. AI models produce clean, readable code; hardware demands predictable execution. That mismatch creates a distinct class of failures, behavioural errors, which are invisible in source review yet visible as jitter, throughput loss, and non-deterministic traversal when code runs repeatedly on an embedded target. WedoLow is one example of a new breed of tooling that signals this shift: instead of only reading code, these tools observe runtime behaviour, surface structural drift (unstable branches, temporary allocations, scattered accesses), and steer regeneration toward forms that preserve semantics while restoring predictable execution. Mentioning WedoLow here is meant to illustrate the direction of the ecosystem rather than to detail an implementation: the broader trend is behaviour-aware validation sitting alongside generation.
High-level description: Behaviour-aware pipelines
Behaviour-aware pipelines for embedded code: what next-generation tools inspect
Behaviour-aware pipelines look beyond source diffs and test assertions: they instrument real runs and quantify execution patterns under realistic workloads. These systems measure timing spread, traversal stability, memory-access patterns, and control-flow variability to diagnose structural drift introduced by automated generation. A well-designed behaviour-aware system has four core properties:
- Project integration. Integrates with the project build and CI so behavioural checks run where code lives, using the actual toolchain, targets, and top functions.
- Structural focus. Targets structural issues (loop placement, temporary workspace, branch hotspots, memory stride) rather than micro-tweaks to individual instructions.
- Drift detection. Detects deviations across iterations (timing envelopes, jitter, and stride instability) and pinpoints the minimal structural causes.
- Machine-readable feedback. Produces actionable, machine-readable diagnostics that the generator or an agent can consume to avoid regenerating unstable patterns.
Together, these features let the toolchain treat behavioural metrics as first-class results: regressions are detected by widened timing envelopes or unstable traversal rather than by failing unit tests alone. The goal is not to replace human judgment but to give generation and reviewers clear, repeatable signals about where structure must change to meet embedded constraints.
Where AI + behaviour-aware tooling is heading
Future direction: generator-plus-critic and behaviour-first CI for embedded projects
AI for embedded systems will move from standalone generators to generator-plus-critic workflows: the generator proposes code and a behaviour-aware critic validates it against measured runtime metrics. Project-aware agents (connected via MCP as a transport) will let the critic run the code on realistic inputs, report timing envelopes, stride stability, and jitter, and require changes before code merges. Behavioural metrics, timing distribution, per-iteration variance, and stride/prefetch stability will become first-class CI gates alongside correctness tests. Behavioural CI gates require careful calibration: use repeated measurements, statistical thresholds, and hardware/thermal controls to avoid flaky failures. WedoLow is a concise example of this direction: tools that combine execution measurement, structural diagnosis, and machine-readable feedback to ensure generated code not only computes the right results but also behaves predictably on hardware. The practical outcome: faster prototyping with reduced risk, because behavioural regressions are caught automatically and corrected before deployment.
Conclusion
AI-powered code generation has become a valuable accelerator in embedded development, enabling developers to create functional C/C++ modules, transforms, and pipeline utilities with remarkable speed. But as modern embedded workloads demand stable timing, predictable memory behaviour, and consistent iteration patterns, the limits of code generated statistically become apparent. Even when AI-produced implementations are logically correct, small structural deviations, extra buffers, scattered traversal, irregular branching, or redundant work accumulate into instability when these workloads run repeatedly on real hardware.
These issues are not flaws in logic; they are flaws in execution behaviour, and they rarely appear during manual review. Embedded systems expose them only during continuous, real-world runtime.
This is where WedoLow provides the missing layer. Instead of relying on visual inspection or static heuristics, WedoLow evaluates how AI-generated code behaves under actual execution. Behaviour-aware tools run the project under representative workloads, capture timing envelopes, memory-pattern diagnostics, and control-flow variability, and surface machine-readable recommendations that guide safe regenerations or manual fixes. Those recommendations are provided to the connected AI agent (MCP functions as the transport); WedoLow pilots that agent with tooling and context so regenerated code aligns with embedded constraints.
As AI continues advancing, coupling generation with behaviour-aware refinement becomes essential. AI accelerates creation; WedoLow ensures the results behave correctly in real embedded workloads. Together, they define a practical and reliable workflow for the current state of AI-powered code generation for embedded systems, balancing rapid development with the execution stability that embedded applications depend on.
FAQs
Why do AI models struggle with embedded constraints?
AI models operate at a high level and don’t understand low-level realities such as timing budgets, cache behaviour, memory layout, or execution flow. As a result, they often introduce inefficiencies like unstable branching or scattered operations that break deterministic behaviour. Embedded systems depend on tightly controlled, predictable loops, something AI cannot guarantee by default.
Does connecting the AI agent via MCP improve determinism and performance?
Yes. When WedoLow pilots an AI agent with project-aware tooling and context (MCP serves as the secure transport), the agent gains controlled access to compilers, profilers, and runtime diagnostics. Instead of guessing, the agent sees real measurements, timing stability, memory-access patterns, and drift signatures, and uses that feedback to refine code. The key point: MCP is the transport; WedoLow is what pilots the agent and turns measurements into safe, validated changes.
Will AI eventually replace manual optimisation?
AI can accelerate optimisation by detecting bottlenecks, identifying inefficient patterns, and suggesting better structures. It removes repetitive manual tuning. But it cannot fully replace human oversight because it still lacks a true understanding of hardware behaviour, edge-case timing, and deterministic execution. Human validation remains essential for safety-critical embedded workloads.
Can AI-generated code be trusted in embedded systems?
AI-generated code can be trusted only after proper optimisation and verification. When loops are tightened, redundant work is removed, and memory access patterns are improved, the resulting code reduces CPU load, minimizes energy consumption, and delivers smoother execution on low-power hardware. With MCP-based feedback and human review, it becomes reliable for embedded use.

.svg)




.svg)