
TL;DR
- AI-generated code has become an increasingly powerful accelerator for embedded developers, enabling rapid creation of functional modules, transformation utilities, and algorithmic components. However, AI-generated code lacks an understanding of how a real embedded system behaves. It does not interpret constraints like memory ceilings, latency budgets, or the timing requirements that govern real-time execution.
- Because of this, AI-generated code often looks correct at the source level yet produces unstable or unpredictable behaviour on actual embedded systems. These inconsistencies typically manifest as timing jitter, fluctuating per-iteration costs, unstable tile traversal, inconsistent memory patterns, and performance degradation, particularly in compute-heavy workloads such as CARS Rasterize, CARS Resample, and motion-planning loops inspired by Ruckig.
- These issues rarely surface during code review. They only become visible when the code runs continuously on the target hardware, where even small inefficiencies accumulate into real performance loss. Embedded systems depend on determinism, not just correctness.
- WedoLow closes this gap by combining its beLow optimization suite with a direct integration to AI agents (MCP is used as the transport). The system analyzes execution behaviour, proposes and validates behaviour-aware improvements, and feeds actionable diagnostics back to the agent so future generations (or engineers) can avoid the same mistakes. The result is embedded C/C++ that remains functionally identical but far more predictable, stable, and efficient.
Introduction
AI-assisted code generation has moved from novelty to daily practice. Modern models can now produce full C/C++ modules, geometric transforms, resampling utilities, and multi-stage pipelines from natural-language descriptions, dramatically accelerating early development, especially in domains with repetitive or patterned logic.
Embedded systems, however, impose constraints that general-purpose software rarely faces. They require deterministic timing, predictable memory behaviour, and stable iteration cost. Even small structural shifts, an extra buffer, a scattered read, a branch that fires intermittently, can destabilize real-time workloads. This becomes clear in pipelines like CARS Rasterize, a tile-based renderer that processes thousands of tiles where each tile must stay within a tight cycle band; in CARS Resample, which performs high-throughput grid and sensor resampling where memory stride and per-row timing must remain consistent; and in Ruckig-style motion planning, where each trajectory update must take nearly identical time to avoid visible actuator jitter.
AI-generated code often looks correct while embedding behaviours that break these expectations. Language models do not reason about cache locality, traversal order, instruction timing, or how microscopic changes accumulate over continuous execution. As a result, code that passes review and works functionally may still introduce timing jitter, throughput loss, or unstable traversal when placed inside a real embedded loop.
This gap between functional correctness and behavioural correctness is where WedoLow operates. By analysing how code actually behaves under execution, timing envelopes, stride stability, memory-touch patterns, and control-flow variability, it identifies structural drift and proposes or validates behaviour-aware refinements. The result is AI-generated C/C++ that remains functionally identical but behaves predictably in the demanding conditions embedded systems require.
The distinction can be summarized visually. While AI-generated code often meets functional expectations, embedded systems demand a deeper level of behavioural correctness that statistical generation does not address.
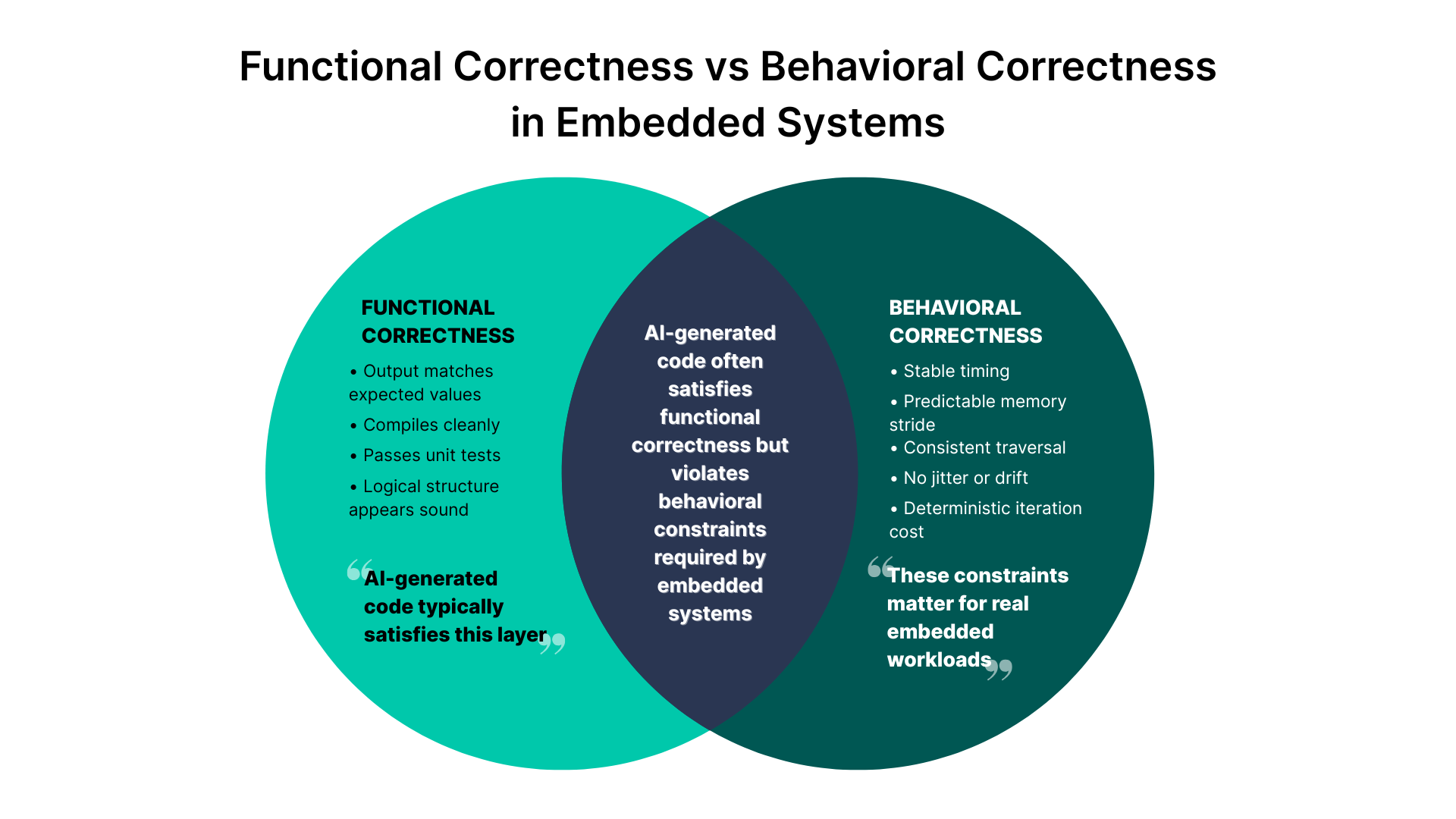
The sections that follow break down how these behavioural failures appear in real embedded workloads and why tools like WedoLow are required to detect and correct them.
What AI-Generated Code Actually Means for Embedded Developers
AI-generated code feels compelling at first glance. It is clean, neatly structured, readable, and logically correct. It resembles well-written utility code that could be dropped directly into an embedded project. Developers can request coordinate transformations, tile iterators, arithmetic utilities, or even complete algorithmic modules, and the AI produces something that compiles and passes basic tests.
But embedded developers implicitly apply a deeper judgment, the judgment that accounts for how hardware behaves. This includes understanding how pipelines handle branching, how memory access shapes execution time, how loop structure affects jitter, and how cache behaviour determines throughput. AI does not possess this judgment. It is not aware of how memory levels behave or how repeated iteration changes a system’s stability.
AI composes code statistically. It creates patterns that resemble correct code rather than patterns optimized for real execution on embedded systems. When it inserts a small conditional inside a loop or adds a temporary vector during the inner pass of a rasterization routine, it does not understand that this might break determinism. The code may still compile and produce the correct output, but its runtime characteristics may vary across frames or depend subtly on input values.
This disconnect becomes especially damaging in compute-intensive pipelines such as rasterization, tile resampling, or trajectory generation, where every iteration matters. Even slight changes in locality, traversal order, or loop structure can raise cycle cost and create frame-to-frame variability. Embedded developers recognize these hazards instinctively; AI does not. As a result, AI-generated code often runs but rarely runs deterministically until it is analyzed and refined using a system like WedoLow, which evaluates the code's actual execution behaviour and restructures it for stable, predictable performance.
Let’s break down where AI struggles and why.
AI Code Lacks Hardware Awareness by Default
AI models do not understand how execution behaviour changes when loops, traversal, or data access patterns shift, or how local memory behaves under different data layouts. They generate patterns that look elegant but may introduce runtime hazards invisible at the source level.
These hazards typically emerge as subtle structural choices inside the generated code: scattered memory access that looks like clean abstraction but breaks locality, temporary buffers created silently inside tile or iteration loops, conditional branches that fire unpredictably across frames, generalized utility functions that disrupt traversal order, and implicit type conversions that increase execution cost.
From a code-review perspective, everything looks harmless. But upon execution, these patterns create unstable timing, jitter, and unpredictable memory behaviour. Embedded workloads amplify these issues because they run continuously, often at fixed real-time frequencies, where stability matters just as much as speed.
In pipelines like CARS Rasterize and CARS Resample, slight changes in access patterns result in variations in the cycle count per tile. In motion-planning loops, one conditional path may take a different number of cycles depending on the runtime input. Across thousands of iterations, these variations accumulate and destabilize the entire system.
Here is an AI-Generated Code Example of CARS Rasterize :
for (int t = 0; t < tile_count; t++) {
float temp_coords[256];
compute_intermediate(tile[t].points, temp_coords);
if (tile[t].is_edge) {
adjust_for_edges(temp_coords, tile[t].size);
}
for (int i = 0; i < tile[t].size; i++) {
output[i] = project_to_surface(temp_coords[i]);
}
}WedoLow’s role begins here. Its beLow suite analyzes execution behaviour, identifies unstable traversal and hidden inefficiencies, and produces machine-readable diagnostics and candidate restructurings. Those findings are surfaced to the connected AI agent (MCP provides the transport), which can regenerate affected sections or present suggested fixes to engineers. This feedback loop prevents the same instability from reappearing in future code iterations.
Correctness Does Not Guarantee Deterministic Behaviour in Embedded Systems
A recurring misconception with AI-generated code is that correctness at the output level implies correctness at the execution level. For embedded systems, this could not be further from the truth. Embedded workloads are not judged solely by whether they produce the right numbers; they are judged by cycle cost, memory access behaviour, execution predictability, and iteration stability.
AI-generated code often produces the right output but changes its execution pattern across frames. Loop timings drift. Temporary buffers appear conditionally. Traversal paths alter based on subtle input changes. Because AI-generated code is largely statistical, it is indifferent to these issues. It may choose one branching structure in one prompt, another in the next. This inconsistency is harmless in backend code but disastrous in embedded workloads.
Real-time systems require the opposite: Stable iteration counts, consistent tile timing, and predictable memory access every cycle, every frame.
This disconnect makes AI-generated code difficult to rely on in embedded systems without a behaviour-aware correction step. WedoLow addresses this gap by evaluating how the code behaves when executed, not just how it looks in source form, and reshaping the structure to produce stable, deterministic performance. By grounding optimizations in measured behaviour, WedoLow keeps execution cost within consistent bounds and maintains predictable behaviour across all input variations.
AI Over-Abstracts and Allocates Too Frequently
AI tends to choose abstraction over specialization. This is natural for a model trained on general-purpose codebases. It favours helper functions, vector-based utilities, dynamic structures, and generalized transformations because they look elegant and reusable.
But embedded code often requires simplicity, tight loops, linear memory access, and minimal temporary allocation.
AI-generated abstractions can easily disrupt the stability that embedded systems depend on. They may introduce temporary buffers that increase overall memory pressure, add operations that unintentionally break data locality, wrap simple logic inside functions that add extra overhead, or rely on generalized types that require additional conversions. In some cases, the AI may even generate recursive structures or hidden dynamic allocations that make timing unpredictable. Even though these patterns look clean at the source level, their execution behaviour often becomes unstable when exposed to real-time constraints.
Each individual abstraction is minor. Combined, they slow the system down and cause per-frame timing variance. They also introduce unnecessary memory activity, increasing latency and energy consumption on constrained embedded devices.
WedoLow’s beLow optimization suite identifies these hidden abstractions. It simplifies control flow, removes unnecessary memory movement, restructures traversal, and restores deterministic behaviour without sacrificing correctness. This behavioural feedback is passed to the AI model through MCP, allowing the model to incorporate it into future generations.
Why Understanding AI’s Limitations Is Critical in Embedded Systems
AI-generated code behaves unpredictably when inserted into pipelines that rely on repeatable execution. In workloads such as CARS Rasterize or CARS Resample, the system evaluates thousands of tiles in tight, bounded loops. Even a small structural deviation introduced by AI, a helper routine placed inside the loop body, an unnecessary transform applied per tile, or a traversal pattern that subtly changes input ordering, immediately appears as drift in per-tile cycle cost. The source looks clean, but the behaviour diverges because the underlying structure no longer aligns with the access patterns these pipelines depend on.
This sensitivity becomes even more pronounced in Ruckig-style motion-generation loops, where the code must maintain consistent iteration timing across sequential updates. An AI-generated conditional that fires only under certain numeric ranges can introduce micro-shifts in loop duration. These shifts accumulate over repeated iterations, causing trajectory updates to lose their mechanical smoothness. The issue is not correctness; the numeric output remains valid, but the execution pattern ceases to be uniform from one update to the next.
None of this instability is visible during code review because the AI-generated code appears logically sound. The hazards exist at the runtime shape level: how the loop advances, how memory is accessed, and when work is performed. AI does not reason about these properties when generating code. It cannot anticipate that moving a buffer initialization inside the inner tile pass of CARS Rasterize will introduce timing variation across tiles, or that reorganizing vector access in a resampling loop will subtly alter the spacing between memory hits.
This is where WedoLow’s approach becomes essential. Instead of treating the code as text, WedoLow evaluates the behaviour the code produces when executed in your project environment. Through the analysis engine below, it detects timing drift between iterations, flags unstable traversal, and surfaces control-flow patterns that AI-generated code often introduces without intent. These behavioural findings are sent to the AI through the MCP transport, allowing it to regenerate the affected sections with a more stable structure.
Deterministic Timing Requirements
Deterministic timing matters most in pipelines that run continuously and expect the same amount of work per iteration. In CARS Rasterize, for example, each tile is processed with the expectation that its cycle cost remains within a tight band across thousands of frames. When AI-generated code introduces small variations, a conditional that only fires on specific pixel ranges, an extra local buffer created for certain tile categories, or a traversal that changes based on input distribution, the tile timing graph begins to spread. The workload still completes, but tiles that once behaved uniformly now land across a wider timing envelope, reducing throughput and breaking predictable scheduling.
The same sensitivity applies in CARS Resample. The resampling process assumes consistent stride and memory-touch patterns to maintain throughput. AI-generated modifications that alter how indices are computed or reorganize temporary workspace usage can shift the per-row processing time. These inconsistencies accumulate into visible throughput dips during large dataset processing, especially when multiple cores or multiple tasks rely on synchronized progress. What looks like a minor structural change in source form becomes a measurable deviation when executed repeatedly.
Motion-planning loops modelled after Ruckig rely even more heavily on stable timing. Each trajectory update must match the previous frame’s update duration to maintain smooth motion. AI-generated code that inserts a subtle branch or reorders arithmetic can cause the update loop to take slightly more or fewer cycles depending on input conditions. Over sequential frames, these micro-variations manifest as jitter in motion trajectories. The result is not numerical failure, but a loss of execution smoothness that real-time systems cannot tolerate.
Here is an AI-Generated Code Example for Ruckig-Style Motion Planning:
for (int i = 0; i < count; i++) {
float acc = compute_acc(state[i]);
if (acc > limit) {
acc = correct_acc(acc, state[i]);
}
float* tmp = malloc(sizeof(float));
*tmp = compute_jerk(acc);
jerk[i] = *tmp;
free(tmp);
}WedoLow resolves these timing inconsistencies by analyzing execution across many iterations rather than inspecting the source code. The beLow engine captures variations in cycle cost, flags irregularity in loop progression, and identifies areas where the AI-introduced structure produces unstable timing. Once identified, WedoLow rewrites the offending sections into stable, predictable forms that maintain identical functional output but eliminate timing drift. These corrections are then surfaced to the AI model through MCP so that the regenerated code avoids reintroducing the same instability. The final result is behaviorally consistent execution that aligns with the expectations of real-time embedded pipelines.
Tight Memory & Cache Constraints
Embedded workloads do not have the memory elasticity or predictable data access patterns of general-purpose servers. Their performance depends on predictable data locality, stable traversal order, and minimizing unnecessary memory movement. Even minor deviations in how memory is accessed can shift cycle cost across iterations, and these shifts accumulate rapidly in pipelines that run thousands of times per frame, especially in CARS Rasterize, CARS Resample, and Ruckig-inspired loops.
AI-generated code is prone to breaking these expectations. It often inserts temporary buffers into inner loops, introduces container patterns with poor locality, or rearranges traversals into non-linear sequences that force the processor to fetch scattered data rather than advancing through contiguous memory. These patterns look harmless in source form, a helper function, a vector push, an extra copy for “clarity”, but at runtime they create unpredictable stalls that only appear when the system is operating at real workload scale.
In CARS Rasterize, for example, the AI-generated transformation added an intermediate coordinate pass inside the tile-processing loop. Although logically correct, this extra buffer disrupted the natural left-to-right memory order of the tile walk. This disrupted consistent execution behaviour across iterations, causing subtle per-tile variation in cycle count. WedoLow’s analysis identified this drift by tracking memory-access sequences and demonstrating that the temporary buffer was forcing repeated re-fetching of tile metadata. Once removed, the original stable locality was restored.
In Ruckig-like motion workloads, memory issues tend to manifest as small, temporary allocations within iterative update loops. In one AI-generated implementation, a short-lived buffer was created each frame to hold intermediate jerk limits. The allocation was tiny, but its presence inside a high-frequency loop introduced observable variance in frame execution time. WedoLow’s optimization removed the allocation entirely by restructuring the calculation to use stack-based, fixed-size storage, restoring both timing stability and predictable memory behavior.
These problems are not coding mistakes; they are the natural result of AI-generated code that lacks understanding of locality, predictable memory behaviour, or per-iteration memory cost.WedoLow’s beLow engine detects these flaws through structural and runtime analysis, then applies targeted changes that reinforce locality, simplify data movement, and stabilize memory-access patterns. With MCP in the loop, these corrections become part of the AI’s regeneration behaviour, preventing similar patterns from reappearing in future code iterations.
The Three Core Risks of AI-Generated Code in Embedded Systems
AI-generated code accelerates development, but embedded workloads expose weaknesses that remain invisible at the source level. When a pipeline runs thousands of iterations per frame, such as CARS Rasterize, CARS Resample, or Ruckig-inspired trajectory updates, even small structural deviations introduced by AI accumulate into measurable instability. These problems fall into three specific categories: hidden inefficiencies, loss of deterministic timing, and performance degradation under load.
Below is a refined breakdown of these risks as they appear in real embedded workloads.
Hidden Quality Inefficiencies
AI-generated code often contains small inefficiencies that look harmless when reading, but small pieces of redundant work that pass code review unnoticed can expand into real overhead when executed repeatedly. These inefficiencies typically appear as unnecessary recomputations, intermediate transforms, or helper routines inserted into inner loops.
In CARS Rasterize, for example, a seemingly harmless coordinate-recalculation step was added inside the tile-processing loop. The logic was correct, but the repeated computation increased per-tile cycle cost and produced subtle variation across frames. These micro-inefficiencies are easy for AI to create because the model lacks awareness of which parts of a pipeline must remain constant from one iteration to the next. WedoLow’s analysis identified the redundant pass and restored a stable, minimal-cost tile traversal after removing the unnecessary work.
Loss of Deterministic Timing
Embedded pipelines depend on predictable iteration behaviour. When AI inserts structural changes, usually a conditional branch, a helper utility inside a tight loop, or a temporary buffer created only under certain input patterns, the timing of the loop begins to drift across frames. The code still produces correct output, but no longer follows a uniform execution path.
This issue becomes obvious in Ruckig-style motion-generation loops. In one AI-generated update function, a tiny conditional inside the main iteration triggered only under specific numeric ranges. The condition appeared inconsequential in source form, but in real execution, it caused the loop’s timing to shift from frame to frame. These micro-shifts accumulated into visible jitter in trajectory updates. WedoLow identified the unstable branching by analyzing timing traces and reshaped the loop into a single, uniform path that maintained stable cycle cost without altering output behaviour.
Performance Degradation
AI-generated code sometimes reorganizes traversal into patterns that look clean but degrade performance under real load. This often happens when the AI changes memory-access order, uses temporary buffers that disrupt locality, or introduces container operations that fragment the access pattern.
CARS Resample exhibited this clearly. The AI-generated version walked input tiles in a scattered pattern, forcing the system to repeatedly fetch non-contiguous memory. Although the mathematical output was correct, the irregular traversal reduced throughput during large-dataset processing and caused unpredictable stalls under heavy load. WedoLow pinpointed the inconsistent access pattern, restored a smooth sequential traversal, and eliminated the timing variability that had been accumulating across tiles.
How WedoLow + MCP Fix the Problems in AI-Generated Embedded Code
WedoLow grounds optimization in measured behaviour rather than guesswork. The beLow suite performs detailed runtime analysis on AI-generated implementations to find structural patterns that cause instability, redundant work in tight loops, temporary allocations in hot paths, irregular traversal in rasterization, or conversion overheads that break vectorization.
Rather than treating MCP as the product, WedoLow uses a direct integration to the AI agent (MCP acts as the transport) to pilot the agent with concrete diagnostics and example optimizations. For each detected issue, beLow produces an actionable recommendation and, where appropriate, a candidate refactor. The connected agent can regenerate the affected region using that context, or present the change for human validation.
Every candidate transformation is then compiled and measured against the baseline. If the change produces measurable behavioural improvement, it is kept; otherwise, it is reverted. The process is iterative and conservative: only validated improvements accumulate. The final outcome is functionally identical to C/C++, whose runtime behaviour is demonstrably more stable and predictable.
Why Manual Review Cannot Catch These AI Issues
Manual review is effective for checking logic, style, and correctness, but it cannot observe how code behaves on real hardware. AI-generated code often looks clean and structurally sound, yet small transformations, an extra buffer, a helper function inside a hot loop, or a subtle branching pattern, can change timing, traversal order, or memory behaviour once the code runs repeatedly on an embedded target.
These issues remain invisible during review because they are behavioural, not syntactic. A reviewer cannot see that a temporary buffer disrupts locality in CARS Rasterize, or that a small conditional inside a Ruckig-style loop causes micro-jitter after thousands of updates. They only become evident when the workload is executed continuously under real constraints, something manual review simply cannot replicate.
This gap is exactly what WedoLow is designed to address. Instead of judging code by its appearance, WedoLow analyzes how the code actually performs. It's beLow engine measures iteration-to-iteration timing stability, memory-access patterns and locality, traversal consistency in tile and sampling loops, and the structural drift introduced by AI-generated abstractions. These signals directly shape embedded-system behaviour, yet they remain undetectable through manual review. WedoLow makes them visible.
These findings are surfaced to the connected AI agent (using MCP as the transport), enabling the agent to regenerate code that aligns with actual hardware behaviour or to present validated suggestions to engineers. As a result, WedoLow turns AI-generated code into measured, predictable, and embedded-compatible logic, something manual review alone cannot reliably achieve.
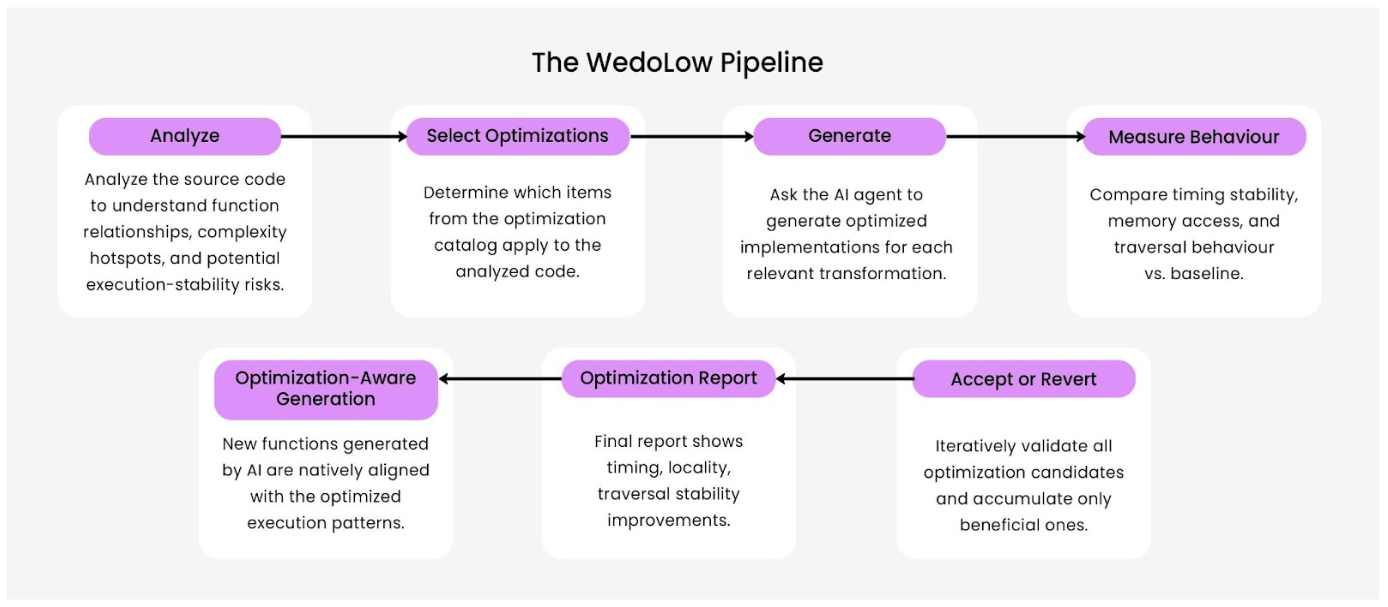
WedoLow follows a structured, behaviour-driven optimization workflow. Rather than applying transformations blindly, it evaluates each optimization against real execution metrics and only keeps those that deliver measurable benefits. The process advances through a seven-stage loop:
1. Analyze the source code
WedoLow inspects the project to understand its structure: map function relationships and complexity, discover hotspot functions, and identify all possible bottlenecks, unstable loops, or inefficient patterns. This step builds a hardware-accurate model of where deterministic behaviour is most at risk.
2. Identify relevant optimizations
From its catalog of optimization techniques, WedoLow checks which optimizations are relevant to the patterns found during analysis (e.g., loop simplification, traversal restructuring, memory-layout cleanup, branch stabilization, allocation removal).
3. Ask the LLM to generate optimized variants
For each optimization deemed relevant, WedoLow asks the LLM (via MCP as the transport) to generate an optimized variant of the affected code region.
4. Compile, measure, and compare behaviour
Each optimized variant is compiled and executed against the real workload. WedoLow measures timing stability, locality, traversal consistency, and performance impact, then compares results to the original.
5. Iterate across all optimizations
If an optimization produces a measurable behavioural gain, it is applied; if not, WedoLow reverts to the original code and proceeds to the next candidate. This analyze → propose → compile → measure → accept/revert cycle repeats across the entire optimization list.
6. Produce a detailed optimization report
When the iteration completes, WedoLow generates a report summarizing which optimizations were applied, the measured behavioural improvements, and how timing, locality, and traversal stability changed compared to the baseline.
7. Provide optimization-aware generation for new code
With the tuned project context (carried forward via MCP as the transport), developers can ask the LLM to generate new functions. Newly generated code is written with the optimized execution patterns and constraints in mind, reducing the need for future rewrites.
How WedoLow Uses MCP to Validate and Improve AI Code
WedoLow’s tuning loop is a measurement-driven, closed feedback system: the project is built and profiled on real hardware, beLow analyzes the runtime traces, and the agent (connected via MCP) proposes targeted code refinements. Each proposed change is compiled and validated on the target; improvements that pass hardware validation are accepted and carried forward as part of the project context. This on-device, iterate-and-validate loop ensures optimizations are grounded in real execution metrics rather than assumptions, and keeps functional behaviour unchanged while improving determinism and throughput.
WedoLow Model Context Protocol
The Model Context Protocol (MCP) is the transport mechanism WedoLow uses to connect a project’s execution context and tooling to a connected AI agent. MCP itself is not the actor; it simply enables the agent to access the project-aware information and tools WedoLow exposes, such as compilers, analyzers, profilers, benchmark harnesses, build metadata, and the top-function context.
Using MCP, the AI agent receives a digest of the project environment (build commands, target platform, top functions, and the optimization candidates surfaced by beLow). With that context, the agent can generate or regenerate code informed by real performance metrics rather than blind heuristics. MCP also carries the measurement results back to WedoLow so each proposed change can be validated against the baseline.
Put plainly: MCP is the secure lane between WedoLow’s tooling and the AI agent; it enables a tool-assisted optimization loop without making MCP the conceptual focus.
Optimization Techniques Provided by beLow
The beLow is designed to identify structural behaviours that reduce determinism and to apply optimizations that match the execution patterns of embedded workloads. Instead of focusing on raw hardware counters or micro-optimizations, beLow targets the structural patterns that shape timing, stability, and throughput.
At a high level, beLow improves the code by restructuring loops to create stable, repeatable iteration paths, refining memory layouts to ensure predictable data movement, and removing redundant operations that accumulate inside loops or tile passes. It further enhances throughput by optimizing data traversal patterns and simplifying type and conversion flows to reduce overhead across the pipeline. In addition, it applies compiler strategies tailored to the specific platform to reinforce determinism during the final build.
These optimizations focus on the behaviours that matter most in embedded systems: stable execution, reduced unnecessary work, and predictable performance across frames. By addressing these structural patterns, beLow ensures that the final code behaves consistently, a critical requirement for any real-time or timing-sensitive environment.
Real Example: Motion-Planning Stabilization (Ruckig)
In a Ruckig-inspired motion-planning loop, the AI-generated implementation was functionally correct but introduced a small structural issue inside the trajectory-update path: a conditional check and a short-lived temporary buffer appeared inside the high-frequency iteration. These additions did not change the numerical outcome, but they caused slight timing variations across frames, the kind of micro-instability that becomes visible only when the loop runs repeatedly on an embedded target.
Using the beLow analysis engine, WedoLow detected this drift by examining the loop’s timing behaviour and identifying where execution was diverging between iterations. The analysis showed that the conditional branch and the temporary workspace were responsible for the inconsistent cycle counts.
WedoLow then applied targeted optimizations to restore stable execution. The loop was reorganized so that the update path remained uniform across all frames, and the temporary allocation was replaced with a table structure that avoided small timing differences between iterations. These changes preserved the exact behaviour of the motion-planning logic while making its execution pattern consistent and predictable.
With MCP in the loop, these findings were fed back to the AI model, which then regenerated the affected section of code with the corrected structure. As a result, the updated motion-planning implementation maintained its functional correctness while aligning far better with the timing stability required in embedded control workloads.
Conclusion
AI-generated code has become a valuable accelerant for development, but embedded systems demand a level of predictability that statistical generation alone cannot guarantee. Even when functionally correct, AI-generated implementations often introduce small structural variations, extra buffers, inconsistent traversal, unstable branching, that quietly shift timing and behaviour when executed across thousands of iterations. These issues rarely appear during review and only emerge when the code runs continuously on real embedded workloads such as rasterization, resampling, or motion-planning loops.
WedoLow addresses this gap by evaluating code based on its measured behaviour rather than its appearance. The beLow analysis engine identifies where AI-generated logic introduces instability, excess work, or irregular memory usage and produces machine-readable recommendations and candidate restructurings. These suggestions can be applied automatically where safe or proposed for human validation (automated where safe; changes are validated before commit). The findings are surfaced to the connected AI agent (MCP is the transport), which uses the project context and performance data to generate future code that better matches embedded-system constraints.
The result is a practical path for integrating AI into embedded development: the speed and flexibility of AI-assisted generation combined with the predictability, stability, and consistent behaviour that embedded systems depend on. WedoLow ensures that AI-produced code not only works, but behaves consistently under the real conditions that embedded applications must meet.
FAQs
Why is AI-generated code risky in embedded systems?
AI lacks awareness of timing, memory layout, and execution flow, so it often introduces small inefficiencies or unstable branching that break deterministic behaviour. Embedded systems rely on predictable loops and consistent performance, making these hidden variations risky in real-time workloads.
How does WedoLow use MCP within the optimization workflow?
MCP serves only as the transport layer connecting WedoLow’s tools to the AI agent. Through this channel, the agent gains access to compilers, analyzers, and profiling tools, enabling it to regenerate code using real behavioural signals rather than guessing. This produces code that better aligns with embedded-system constraints.
What is the role of AI in process optimization for embedded workloads?
AI assists process optimization by automatically analyzing patterns in code, identifying inefficiencies, and suggesting improved structures that reduce manual tuning. It can detect bottlenecks, propose better workflows, and accelerate repetitive tasks. However, AI-generated suggestions still need validation, because the model does not understand real hardware behaviour or deterministic execution requirements.
Does hardware-driven optimization reduce cost & energy usage?
Yes, optimizing loops, removing redundant work, and improving data access lowers CPU load and reduces unnecessary memory movement. This leads to smoother execution, lower energy consumption, and better efficiency on low-power embedded hardware.

.svg)




.svg)